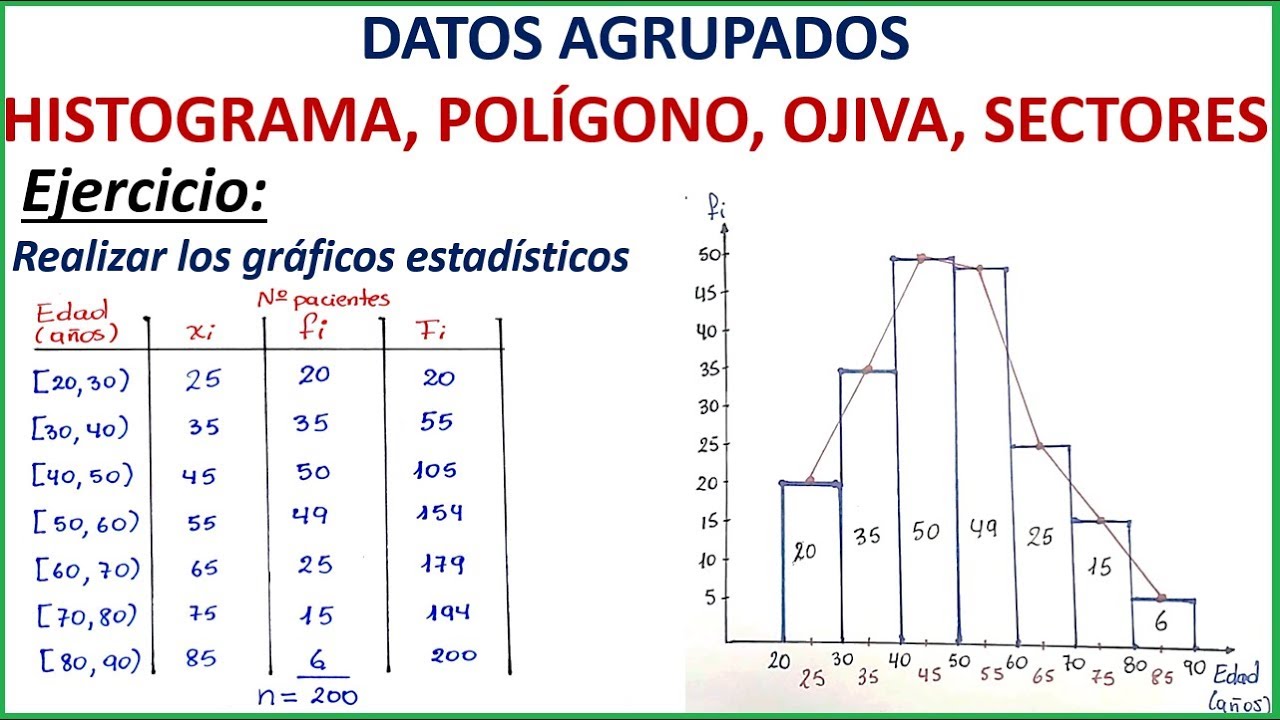
Datos agrupados
Cuando el tamaño de la muestra es considerable o grande y los datos numéricos son muy diversos, conviene agrupar los datos de tal manera que permita establecer patrones, tendencias o regularidades de los valores observados. De esta manera podemos condensar y ordenar los datos tabulando las frecuencias asociadas a ciertos intervalos de los valores observado.
Cuando los valores de la variable son muchos, conviene agrupar los datos en intervalos o clases para así realizar un mejor análisis e interpretación de ellos.
Los datos agrupados en frecuencia son los que se distribuyen u organizan en una tabla de frecuencia (La frecuencia es igual al número de veces en que se repite cada valor en una serie de datos.), así, Por medio de ella, es fácil identificar la cantidad de respuestas repetidas.
Los datos agrupados por intervalos son los que se organizan
dentro de un rango y se delimita su amplitud por límites establecidos. Así, por
medio de esta, es fácil identificar la cantidad de elementos en un determinado
rango de valores.
Rango: Llamamos rango al número de unidades de variación presente en los datos recopilados y se obtiene de la diferencia entre el dato mayor y el dato menor. Se representa con la letra R.
K: Número de intervalos, el cual siempre debe ser un número entero. Razón por la cual se deberá redondear el resultado al entero más cercano.
Valores
|
k
|
Menor 50
|
5 – 7
|
50 – 100
|
6 – 10
|
100 – 250
|
7 – 12
|
Más 250
|
10 - 26
|
Longitud: Es la amplitud de un intervalo es la diferencia entre el límite superior y el límite inferior. La longitud (L) de los intervalos puede calcularse mediante la expresión:
L=R/k
Intervalos de Clase: Son los intervalos en los que se agrupan y ordenan los valores observados. Cada uno de estos intervalos está delimitado (acotado) por dos valores extremos que les llamamos límites. Los intervalos de clase son conjuntos numéricos y deben ser excluyentes y exhaustivos; es decir, si un dato pertenece a un intervalo determinado, ya no podrá pertenecer a otro, esto quiere decir excluyentes y además todos y cada uno de los datos deberá estar contenido en alguno de los intervalos, esto les da el valor de exhaustivos.
El primer intervalo se construye de la siguiente manera: Habrá de iniciar con el dato menor, el cual será el extremo inferior del intervalo; el otro extremo se obtiene de la suma del dato menor y la amplitud, con este mismo valor iniciamos el segundo intervalo, del cual el segundo extremo se encuentra sumando al valor anterior la amplitud y este proceso se repite sistemáticamente hasta completar el total de intervalos.
El número de intervalos de clase depende del número de observaciones. Una mayor cantidad de datos requiere un mayor número de clases. Los intervalos de clase deben estar definidos por límites que permitan identificar plenamente si un dato pertenece a uno u otro intervalo. Estos límites son los valores extremos de cada intervalo. Límite inferior: Es el valor menor de cada intervalo, se denota por Li Límite superior: Es el número mayor de cada intervalo, se denota por Ls.
Límite inferior: Es el valor menor de cada intervalo, se denota por Li.
Límite superior: Es el número mayor de cada intervalo, se denota por Ls.
Marca de clase (xm): Se refiere al Punto Medio del intervalo y a través de él representaremos a todo el intervalo y una de las maneras de calcularla es promediando los valores límite de cada intervalo, su fórmula es:
xm= Li + Ls / 2
Ejemplos: